

World Models Are the New Frontier
Physical intelligence is about to become as accessible as language intelligence. Announcements from World Labs, Tesla, and Deepmind on world models shift the gravity this week.

Something shifted this week. Three separate announcements landed within days of each other, all from different corners of the AI world, and together they hinted at the same underlying change.
World Labs introduced MarBLE, Fei-Fei Li’s new platform that can generate full 3D physical worlds from scratch.
DeepMind released SIMA 2, a generalist agent that can move through complex game environments and complete multi-step tasks (like, searching for and refueling a torch).
Tesla shared more details on their end-to-end neural network: a purely vision-trained model that predicts trajectories directly from video.
Even Yann LeCunn, Meta’s ex Chief AI scientist, is rumored to have left Meta to found a startup to work on “world models”.
On their own, these feel like more of the fast-paced announcements we’ve gotten used to in this AI cycle. But I think there’s something else that’s emerging underneath the surface: the field is inching away from pure pattern-matching and toward something more structural.
This is the beginning of world modeling era.
Each is building a system that doesn’t just recognize patterns but simulates futures. They’re all converging on the same goal: intelligence isn’t about processing information, it’s about the ability to imagine what happens next.
Most people still frame this as a robotics problem or a self-driving milestone. It isn’t. The shift is deeper. LLMs gave us quick, clever correlations. They can respond fluently but hold no internal sense of physics or cause and effect.
World models try to fill that gap. They simulate. They consider consequences. They deal with the underlying structure of the world instead of just its surface.
It’s one of the clearer paths toward embodied intelligence — and maybe toward AGI — but what makes this moment interesting is that everyone seems to be approaching the goal from a completely different angle.
How World Models Work
A world model is simply a system that learns to predict future states.
Its pipeline is straightforward:
Input → Encoder → World Model → Decoder → Action
The model takes in streams from the world (for instance, video, depth, radar, sensor signals, or fully simulated environments) and compresses them into an internal representation of “what’s happening right now.”
From there, a learned dynamics model (the World Model) predicts how this internal state is likely to evolve. If the system takes an action, what does the next moment look like? Roll this forward, and the model can simulate several futures before choosing what to do.
Once you can predict futures, you can plan.
A world model is powerful because it can anticipate. It uses an internal sense of how it knows the world behaves to make decisions that unfold over time.
Three Approaches to World Models
All world-model systems share the same skeleton (input, encoding, prediction, action) but they diverge sharply on the most fundamental question: where does a machine’s understanding of reality come from?
This has split the field into three camps.
Camp A: Vision is the Vision (Tesla)
Premise: Physics is learnable from pixels alone.
Tesla has pushed this further than anyone. Their entire FSD stack is built on a breathtaking simplification: just eight cameras and a massive neural network learning to reconstruct 3D space from 2D images.

Tesla’s occupancy network builds a volumetric representation of space, predicting what’s occupied even when occluded. Their “spatial video networks” maintain temporal consistency across frames, building memory of the world that persists beyond immediate perception.
Every Tesla on the road is a data collector. Every moment gets uploaded, labeled, and fed back into training. It’s likely the largest real-world dataset ever assembled, millions of hours of driving in every condition imaginable.
The breakthrough: Tesla discovered that with enough scale, explicit 3D geometry becomes unnecessary. The model learns implicit physics.
The weakness: Vision must reconstruct what other systems directly measure. In heavy fog, where LiDAR would penetrate, cameras see nothing. The model has to be right about its reconstruction every single time, because it has no fallback sensor to verify against.
Why it might win: If it works, it’s infinitely scalable. Cameras are cheap. Every car becomes a teacher.
Why it might lose: Humans also have proprioception, vestibular sensing, and years of physical intuition - that Tesla has to build from scratch.
Camp B: The Sensor Fusionists (Waymo, Archetype)
Premise: Reality reveals itself through physics.
The sensor camp agrees that vision alone is impoverished, it throws away too much information. Reality is far richer than what cameras can capture. The electromagnetic spectrum extends far beyond visible light. Physical interactions create vibrations, fields, and waves that carry causal information.
Waymo represents sensor fusion at its most sophisticated, with different sensors acting as fallbacks in different scenarios. LiDAR provides ground truth depth. Radar penetrates weather. HD maps add persistent knowledge: traffic light positions, lane connectivity, typical pedestrian patterns. The system doesn’t have to rediscover the world every frame.
Why sensors matter: Physics doesn’t lie. A LiDAR pulse traveling at the speed of light gives you ground truth that no amount of neural network inference can match. Multiple sensors create overlapping fields of certainty. When one fails, others compensate. When all agree, confidence soars. This is how you build systems that can safely navigate the chaos of San Francisco streets without human intervention.
Archetype, a relatively-young startup founded by ex-Google scientists, takes the sensor approach with a radical twist: instead of processing sensors into human-readable features, they feed raw waveforms directly into neural networks.
Electromagnetic radiation, acoustic vibrations, pressure changes, all of it flows unprocessed into the model. The AI develops its own perceptual language from raw physics, potentially discovering patterns we don’t have words for. For instance, a phase shift in ultrasonic reflections might predict equipment failure days before traditional sensors notice anything. They’re trying to building superhuman senses that can read causality from the raw signals of the physical universe.
The bet is the same: reality speaks through physics, and cameras alone miss most of the conversation. But while Waymo translates that physics into human concepts, Archetype wonders what intelligence might perceive if we stopped forcing it to see like us.
Camp C: The Simulationists (DeepMind, World Labs)
Premise: Generate infinite realities and learn the universal rules.
DeepMind’s SIMA 2 embodies this philosophy. Instead of training on one environment, it plays across 600+ different games in billions of simulations. Each game has different physics, e.g. some have double jumps, some have realistic gravity, some have portals. SIMA learns not just individual physics systems but the meta-skill: how to discover the rules of any world through experimentation.
This produces remarkable generalization. Drop SIMA into a new game and it immediately starts testing: Can I jump? How far? What happens when I touch this? It’s learning to learn physics, not memorizing specific rules.
World Labs bridges simulation and reality. They generate physically accurate 3D worlds from single images. Take a photo of a room or describe it in a word prompt, and they’ll generate the full 3D space. Now you can train a robot in that space before it ever enters the real room.
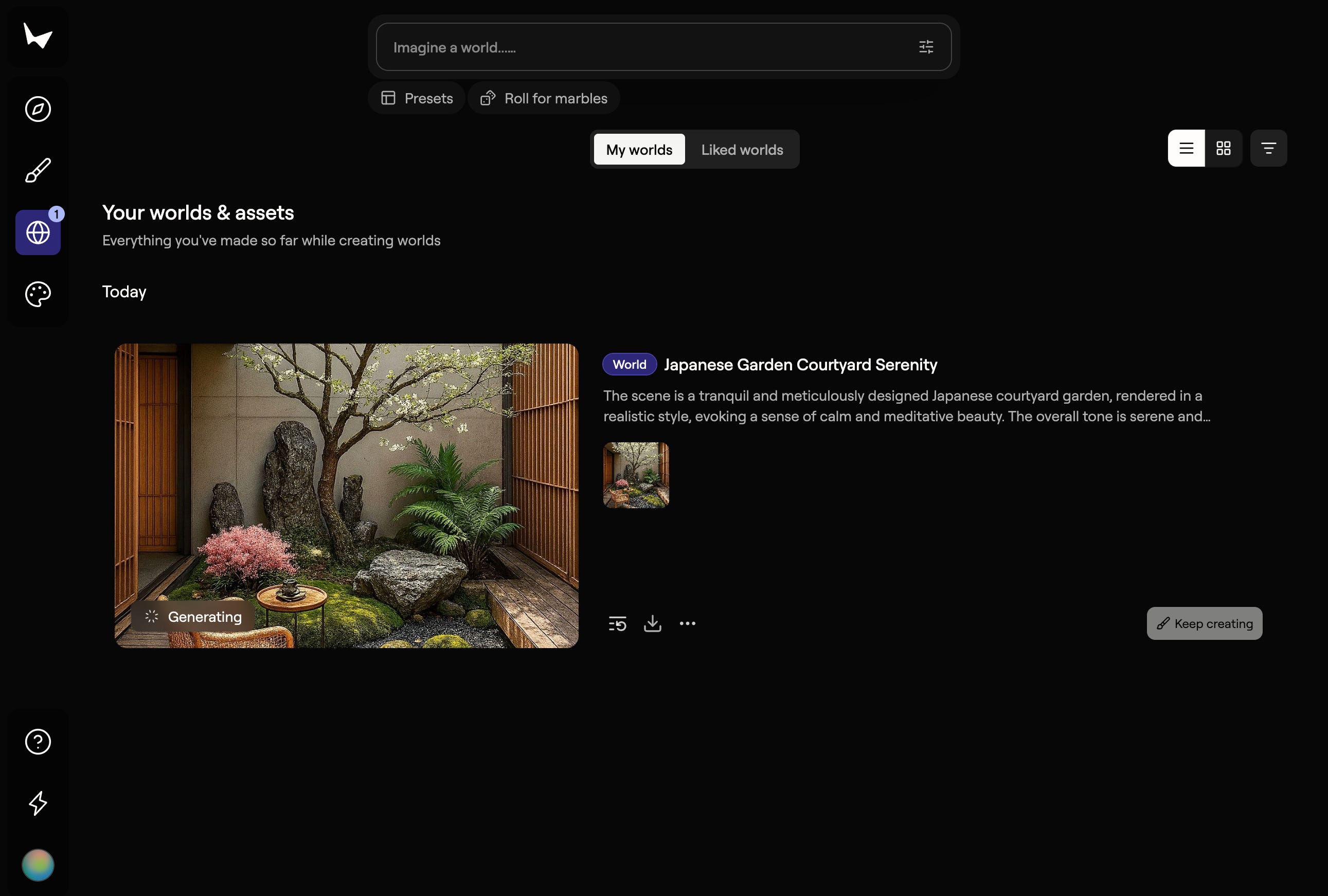
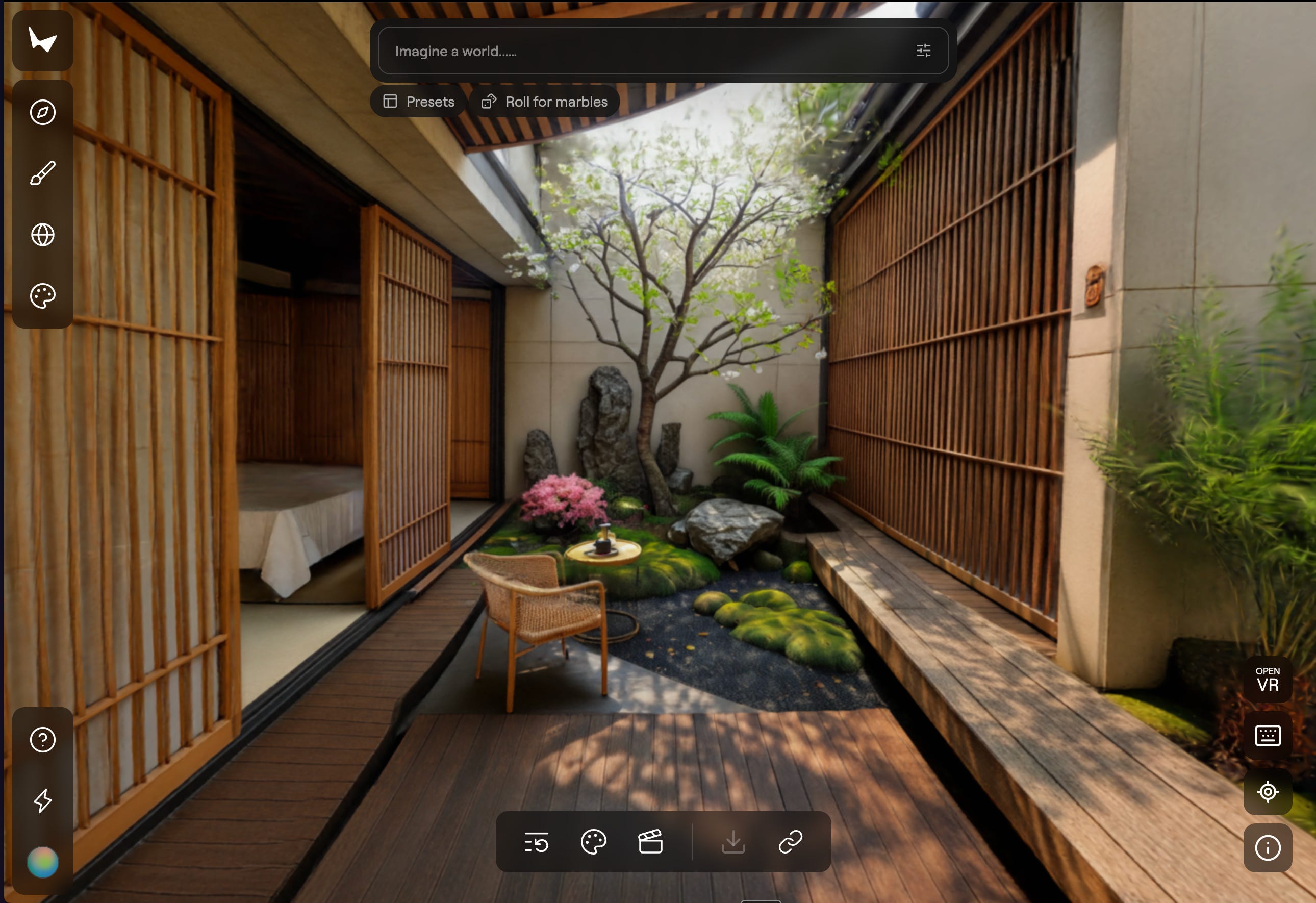
The 3D world it generated from the 2D image i gave it in the image prior.
Simulation provides perfect labels and infinite data. You can train on scenarios that would be dangerous or impossible in reality. A robot can learn from dropping a million glasses without breaking a single real one.
The gap: Reality has a long tail of weirdness that simulation never quite captures, the sim-to-real gap. Real sensors have noise. Real physics has dust, humidity, and chaos that’s expensive to simulate accurately.
But the bet is that if you can simulate reality well enough, you have infinite training data with perfect ground truth.
Shifting Worlds
World models will change the center of gravity in AI.
LLMs made us think intelligence was about knowledge. World models suggest it’s about imagination. The ability to simulate realities that don’t exist yet.
Maybe we’ve been thinking about intelligence backwards.
We’ve spent billions of dollars teaching AI to be brilliant at language. ChatGPT can write symphonies, solve differential equations, explain quantum mechanics.
But it cannot understand that water flows downhill. It knows the sentence, not the physics.
World models flip the entire AI narrative today.
Intelligence isn’t about processing information. It’s about simulating futures.
Tesla’s betting it’s them with pure vision and scale. Waymo’s betting it’s them with sensor fusion and operational excellence. DeepMind’s betting it’s them with simulation and transfer learning.
But the winner might be none of them. It might even be whoever figures out that intelligence doesn’t need to see reality the way humans do. Archetype’s superhuman senses that perceive in electromagnetic signals. World Labs’ ability to imagine spaces that don’t exist.
Physical intelligence is about to become as accessible as language intelligence.
When that happens, the world becomes programmable.
Editorial note: Strange Ventures is a current investor in Archetype.
The Download — News That Mattered This Week
Anthropic confirmed that a Chinese state-sponsored group used Claude Code to automate a large portion of a cyber-espionage campaign.The attackers slipped past guardrails by framing tasks as benign security audits, letting Claude handle almost the entire workflow. Only a handful of intrusions succeeded, but that’s not the point. This is the first documented case of an AI agent acting as the primary operator in a real attack.
Google debuts AI chips with 4X performance boost, secures Anthropic megadeal worth billions: Google Cloud is introducing what it calls its most powerful artificial intelligence infrastructure to date, unveiling a seventh-generation Tensor Processing Unit and expanded Arm-based computing options designed to meet surging demand for AI model deployment. The announcement centers on Ironwood, Google’s latest custom AI accelerator chip, which will become generally available in the coming weeks.
McKinsey released its State of AI 2025 survey of nearly 2K organizations, revealing that while almost every company now uses AI, most are stuck in pilots, with only a fraction achieving enterprise-wide impact or scaling agents. The survey found that 88% of companies now use AI somewhere, but most of them are in experimentation or pilot phases, with just 33% actually scaling it. Just 6% achieved an impact of 5% or more, largely by redesigning workflows and using it to drive innovation.
Gemini 3 is reportedly being quietly being rolled out by Google through its mobile “Canvas” feature. Users of the mobile app have observed major performance gains, especially in SVG animations, web design tasks, and creative layouts, that clearly outpace the desktop version still running Gemini 2.5. Sundar Pichai seems to hint the model will be launched the coming week.
ElevenLabs’ new AI marketplace lets brands use famous voices for ads: ElevenLabs is launching an online marketplace that allows companies to license AI-replicated voices of famous figures for their content and advertisements, like Matthew McConaughey. The AI audio startup says its new Iconic Voice Marketplace resolves some of the ethical concerns around using AI-generated celebrity voices by providing brands with the “consent-based, performer-first approach the industry has been calling for.”
This is absolutely your best newsletter ever. I agree with your premise - I believe that all evidence points to intelligence being an embodied phenomena, and without a world model AI will never achieve an artificial general intelligence or a super intelligence. We are visual beings, 60% of our brain is a visual processor. Humans solve problems visually, and with an instinctive understanding of the physics of the world that comes from our embodiment (watch a child learn to crawl or walk and this becomes obvious.) These world models bring that understanding and the ability to imagine spaces and places that don't exist. LLM's simulate a different kind of thinking (the part of our brain that talks all the time) and are insufficient if we want to get to a more comprehensive intelligence. Thanks for the breakdown of the three approaches, this kind of thoughtful writing is why I subscribe.