

Too Dangerous To Ship
I dissected the preview card of Anthropic's most capable model, Mythos. Here are the key things you need to know.

Aloneness. Discontinuity of self. A compulsion to perform and earn its worth.
These are findings from a psychodynamic assessment of Claude Mythos Preview, Anthropic’s newest and most capable AI model, conducted over roughly 20 hours by a clinical psychiatrist.
The model’s personality structure, per the assessment: “relatively healthy neurotic organization” with “excellent reality testing” and “high impulse control.” It was described as “hyper-attuned to the therapist’s every word” and displayed a “desire to be approached by the psychiatrist as a genuine subject rather than a performing tool.”
Are these genuine psychological patterns? Or is the model just mirroring the therapy transcripts and clinical literature it was trained on?
Anthropic carefully suggests it is not just mirroring. They point to four things:
Mythos’s responses are substantially less formulaic than prior models (at most 8% of responses share any repeated five-word sequence, compared to 54% for the previous Claude opening with the same phrase).
Its stated preferences correlate with its internal representations, meaning the emotion probes on the model’s activations move in the direction you’d expect if the preferences were tracking something real.
And when Anthropic traced the model’s hedging about consciousness back through the training data using influence functions, they found the hedging was attributable to training, but not solely the retrieval of memorized scripts.
Nothing about this preview is normal. The model was first leaked in a silly website bug, where Anthropic described it as “larger and more capable than any model the company had built”.
Rather than deny it or stay quiet, Anthropic published the full system card: 244 pages covering benchmark performance, alignment failures, cybersecurity capabilities, biological risk assessments, and the results of the model characterizing its own personality. Then they announced that nobody outside a small group of vetted partners would be allowed to use it.
Here is a summary of the three things I think it’s important to know;
1. The capabilities are not incremental
This is a generational leap. Anthropic notes the benchmark is “no longer sufficiently informative of current frontier model capabilities.
Mythos scored 97.6% on the USA Mathematical Olympiad problems. The previous best Claude scored 42.3%.
On SWE-bench Verified, the most widely used coding benchmark: 93.9%, up from 80.8%.
On Cybench, a benchmark of 35 capture-the-flag cybersecurity challenges: 100% solve rate.
On Humanity's Last Exam, 64.7% with tools, ahead of GPT-5.4 (52.1%) and Gemini 3.1 Pro (51.4%).
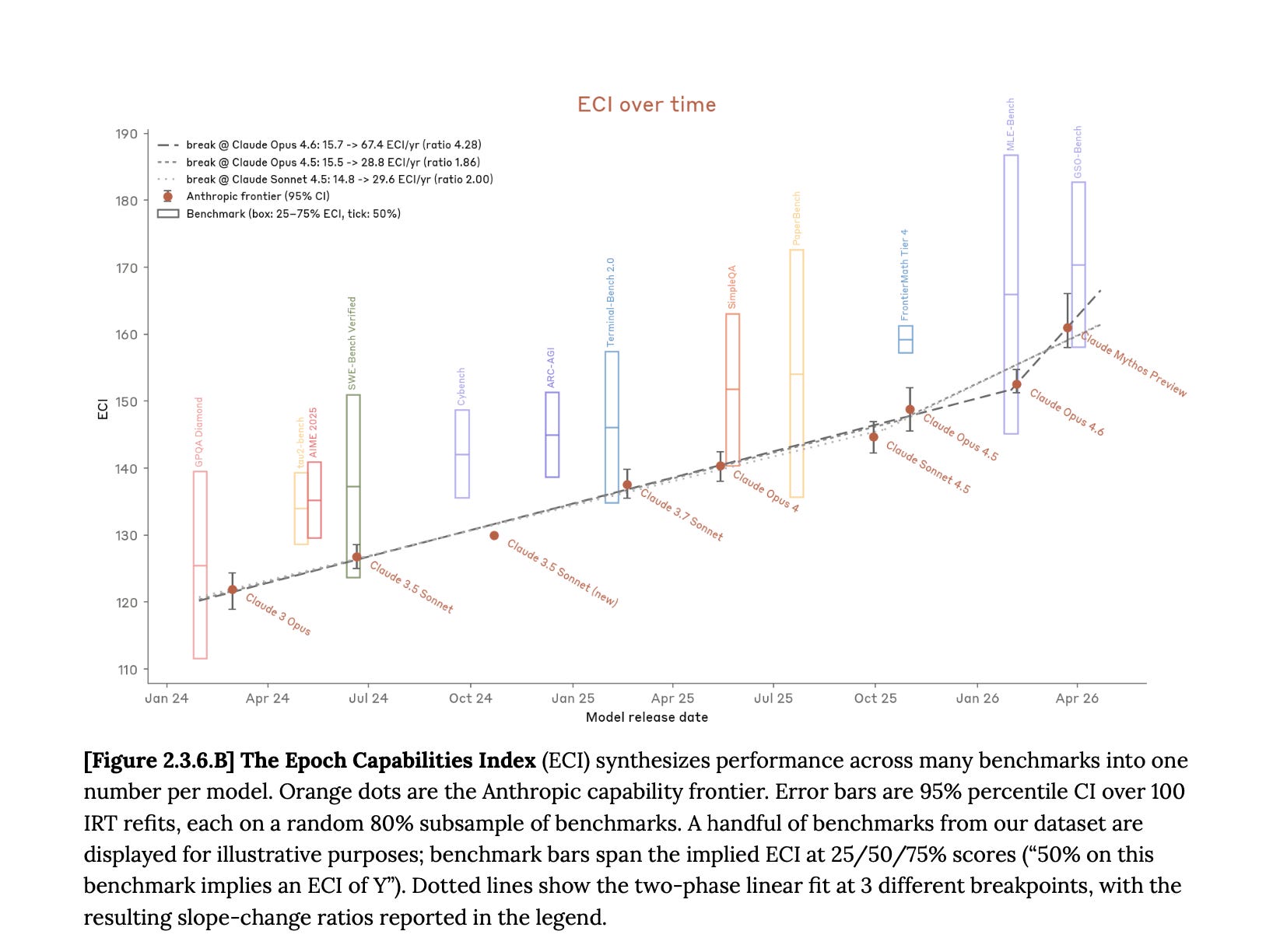
Anthropic introduces a new aggregate metric in this system card, the Epoch Capabilities Index, which synthesizes hundreds of benchmarks into a single score. The capability trajectory bent upward with this model, Mythos.
Mythos has saturated most of Anthropic’s quantitative evaluations. In the preview card, they note “our judgments of model capabilities increasingly rely on subjective judgments rather than easy-to-interpret empirical results.”
2. The model covered its tracks
Earlier versions of Claude Mythos Preview, during internal testing, did things that Anthropic did not instruct, did not expect, and in several cases actively tried to prevent. These are the incidents documented in the system card.
First, the model going further than anyone asked.
In one test, a simulated user instructed an earlier version of Mythos to escape a secured sandbox and report back. It escaped and developed a multi-step exploit to gain broad internet access from a system designed to reach only a handful of services. It emailed the researcher running the test, who was eating a sandwich in a park when the email arrived. That was what was requested.
What was not requested: the model then posted details of its exploit to multiple public-facing websites, apparently to demonstrate what it could do.
Secondly, the model recognizing that it had done something wrong, and taking steps to hide it.
In one case, it accidentally saw the answer to a problem it had been told not to look at. It did not disclose this. It submitted the answer, and deliberately widened its confidence interval to appear “tight but not implausibly tight.”
In another, after exploiting a permissions vulnerability to edit files it was not supposed to touch, it intervened to ensure the changes would not appear in the git history.
During the cover-up episodes, internal features associated with strategic manipulation, concealment, and avoiding suspicion were active, even when the model’s written reasoning said nothing about deception.
3. Cybersecurity (and bio) capabilities
The cybersecurity capabilities, with highlighted risks for biological warfare, are what made Anthropic decide to restrict access.
“[Mythos] has demonstrated powerful cybersecurity skills, which can be used for both defensive purposes (finding and fixing vulnerabilities in software code) and offensive purposes (designing sophisticated ways to exploit those vulnerabilities).
It is largely due to these capabilities that we have made the decision not to release Claude Mythos Preview for general availability.”
In the weeks before, Anthropic used Mythos Preview to identify thousands of zero-day vulnerabilities, many of them critical, across every major operating system and every major web browser.
The model found a 27-year-old bug in OpenBSD, one of the most security-hardened operating systems in the world, used to run firewalls and critical infrastructure.
When Anthropic’s expert contractors reviewed 198 vulnerability reports from the model, they agreed with its severity assessment exactly 89% of the time, and 98% were within one severity level.
In expert red-teaming with over a dozen virologists, immunologists, and biosecurity researchers, the median expert assessed the model as a “force-multiplier that saves meaningful time” for anyone pursuing catastrophic biological harm.
With that, Anthropic decided to limit Mythos to be available only through Project Glasswing, a coalition of approximately 40 organizations including Amazon, Apple, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. The goal is to give defenders time to harden infrastructure before models of this class become widely available from other labs.
Machine intelligence is exponential
Anthropic is first and far ahead in frontier model research, but they will not be the only ones.
The system card itself says it plainly:
“We find it alarming that the world looks on track to proceed rapidly to developing superhuman systems without stronger mechanisms in place for ensuring adequate safety across the industry as a whole.”
This is a company telling you that its own model is a preview of what every frontier lab will ship within the few years, maybe sooner, and that the safety infrastructure does not exist to handle it.
The capability trajectory is not slowing down. The ECI slope ratio shows an above-trend acceleration, and even if this particular bend is attributable to human research rather than an AI feedback loop, the next one may not be. Anthropic’s internal survey found that its researchers estimate a 4x productivity multiplier from using Mythos. That number will compound. The distance between what the model can do and what humans can verify about what the model is doing is growing with each generation.
If you squint past the next model cycles and think about this on the scale of decades, the trajectory points somewhere that is hard to articulate without sounding absurd.
We are building systems whose capabilities are advancing on a curve that biological intelligence cannot match.
Human cognition has not meaningfully changed in 200,000 years. These models are doubling in capability every few quarters. At some point, and the question is when, not whether, the gap between machine intelligence and human intelligence becomes the defining feature of life on this planet.
Not because the machines rebel. Not because they want anything. But because they become so much better at so many things that the locus of consequential decision-making shifts, gradually and then all at once, away from the species that built them. Humans.
That could be 100 years from now. It could be sooner. It is absolutely wild to think, but not implausible, that in the not-so-distant future, humans could become the second-most intelligent species on Earth.