

The Token Whales Behind the Inference Boom
Inference infrastructure revenues suddenly went vertical. A handful of AI-native applications may be driving the entire boom.

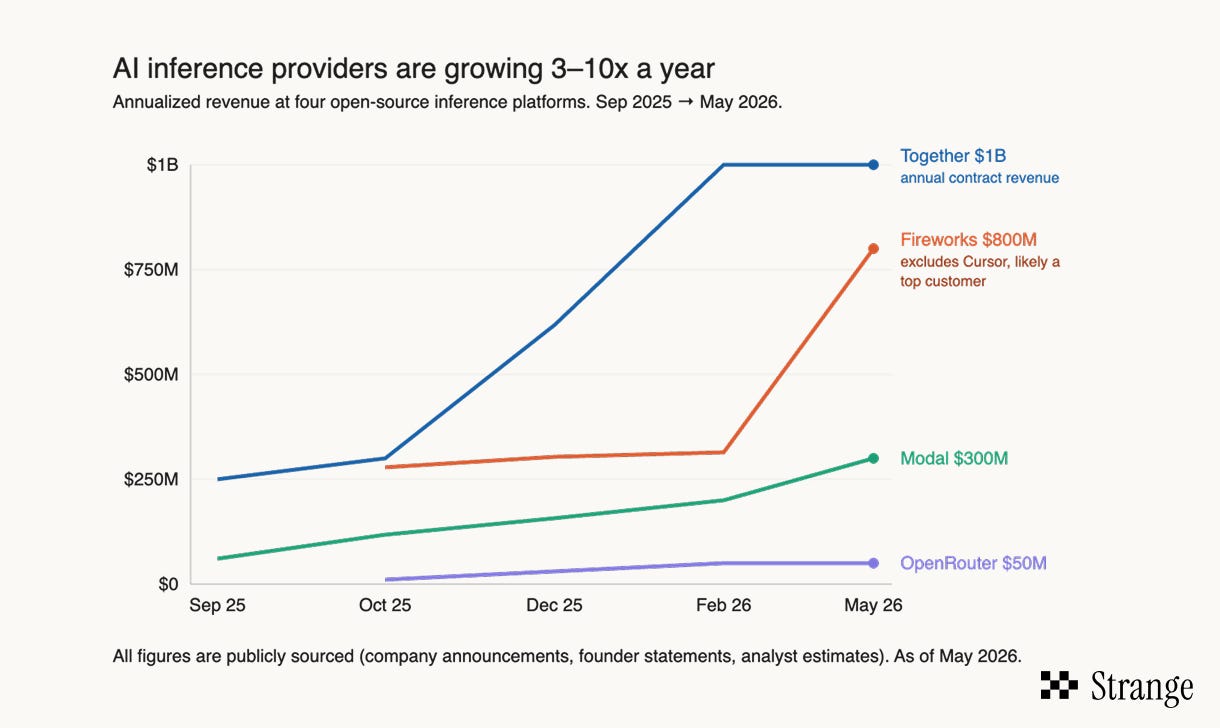
Inference platform revenues have gone hyperbolic in the last year. A small number of AI applications, or token whales, are suddenly consuming infrastructure at industrial scale.
Fireworks climbed from roughly $280M to $800M ARR (notably excluding revenues from what might be their biggest customers, Cursor). Together is reporting 10x YOY revenues, including a $1B contract with a token whale customer. Modal reportedly grew 5x from roughly $60M to $300M ARR since September last year.
The interesting part is that it wasn’t just one company that broke out. Companies across the inference stack all started showing the same shape at the same time: more tokens, higher throughput, larger workloads, steeper revenue curves.
And it doesn’t appear to be driven by exponentially more new users showing up. It appears to be driven by the same users consuming radically more compute.
This is a strong indicator that AI workloads are clearly starting to hit an inflection point. The shift appears to be driven by agents and reasoning-heavy workloads, which can consume hundreds of thousands, or sometimes millions, for a single task.
Baseten said inference volume grew 100x in a year. Google reported Gemini processing 16 billion tokens per minute, up 60% quarter-over-quarter. AWS said Bedrock processed more tokens in Q1 than in all prior years combined.
The Token Whales
Inference demand appears to be far more concentrated than most people realize.
A small number of AI-native applications are likely driving a disproportionate share of inference spend, especially in coding.
Fireworks explicitly excludes Cursor revenue from some reported figures. Together disclosed a single customer contract worth more than $1B. Most of their other enterprise contracts reportedly sit closer to the $1 million mark.
There are clearly a few token whales materially distorting the curve, and who partner with multiple platforms to gobble up compute.
And these token whales have made a strong shift toward open-weight models over the last 12 months, away from closed frontier APIs. Most likely for economics. Spend that previously flowed directly to OpenAI or Anthropic is increasingly being routed through open models plus specialized inference infrastructure.
Cursor’s coding model Composer runs on Kimi K2.5, an open-weight Chinese reasoning model served through Fireworks. Open-weight models reportedly went from less than 2% of OpenRouter traffic to more than 45% in roughly a year.
This helps explain why the independent inference layer suddenly looks like it’s experiencing explosive growth.
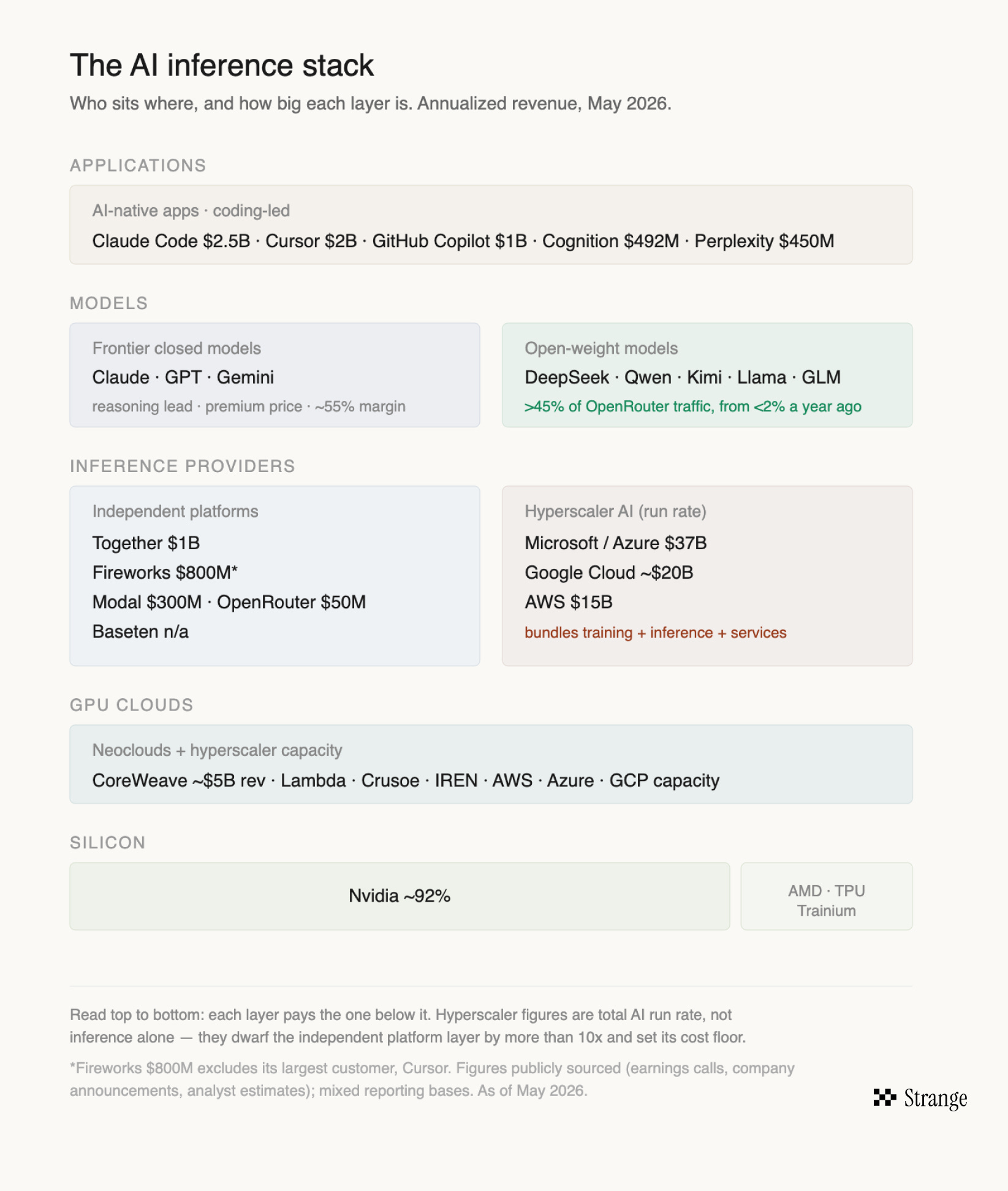
While the hyperscalers are still vastly larger (Microsoft, Google Cloud, and AWS each operate AI cloud businesses that dwarf the entire independent inference ecosystem) the largest AI-native applications increasingly aren’t defaulting to hyperscaler-managed inference stacks.
They want tighter control over latency, routing, serving, model behavior, and ultimately economics. The more inference becomes core product infrastructure, the less attractive generalized platforms become.
That created the opening for companies like Fireworks, Together, Modal, Baseten, and others who are willing to deeply optimize around a customer’s specific workload (like Cursor’s Fireworks partnership for RL inference) instead of offering one-size-fits-all managed infrastructure.
But the boom also has an Achilles heel.
The AI application whales driving this explosion in inference demand could ultimately determine the fate of the inference platforms themselves.
The bull case is that inference platforms become the Snowflake of the AI stack: specialized infrastructure layers that sit above commodity compute and build enduring value through performance, optimization, and workflow depth.
The bear case is that the largest AI-native applications eventually internalize those capabilities themselves. Owning inference increasingly looks like the next logical layer of optimization.
Which makes this moment feel both very real and strangely fragile at the same time.
The inference boom is real. But so far, it appears to be powered by a surprisingly small number of AI-native token whales, customers large enough to eventually build the inference stack themselves.