

The Stranded Asset
How the AI inference boom might leave a generation of data centers behind.

Last week, Google announced its eighth-generation TPUs and split the chip family in two: TPU 8t for training and TPU 8i for low-latency inference at agent-scale, the first time in the TPU program's decade-long history that Google has shipped two distinct chip designs in the same generation.

At GTC 2026, Nvidia did the same, unveiling the Groq 3 LPU, its first inference-specific chip, built on the IP from a $20 billion deal with Groq. Meta, in March, unveiled four successive generations of its MTIA inference chips.
Three of the most consequential chip programs in the industry have arrived at the same conclusion in the same year: that inference as a workload is distinct enough to demand its own architecture.
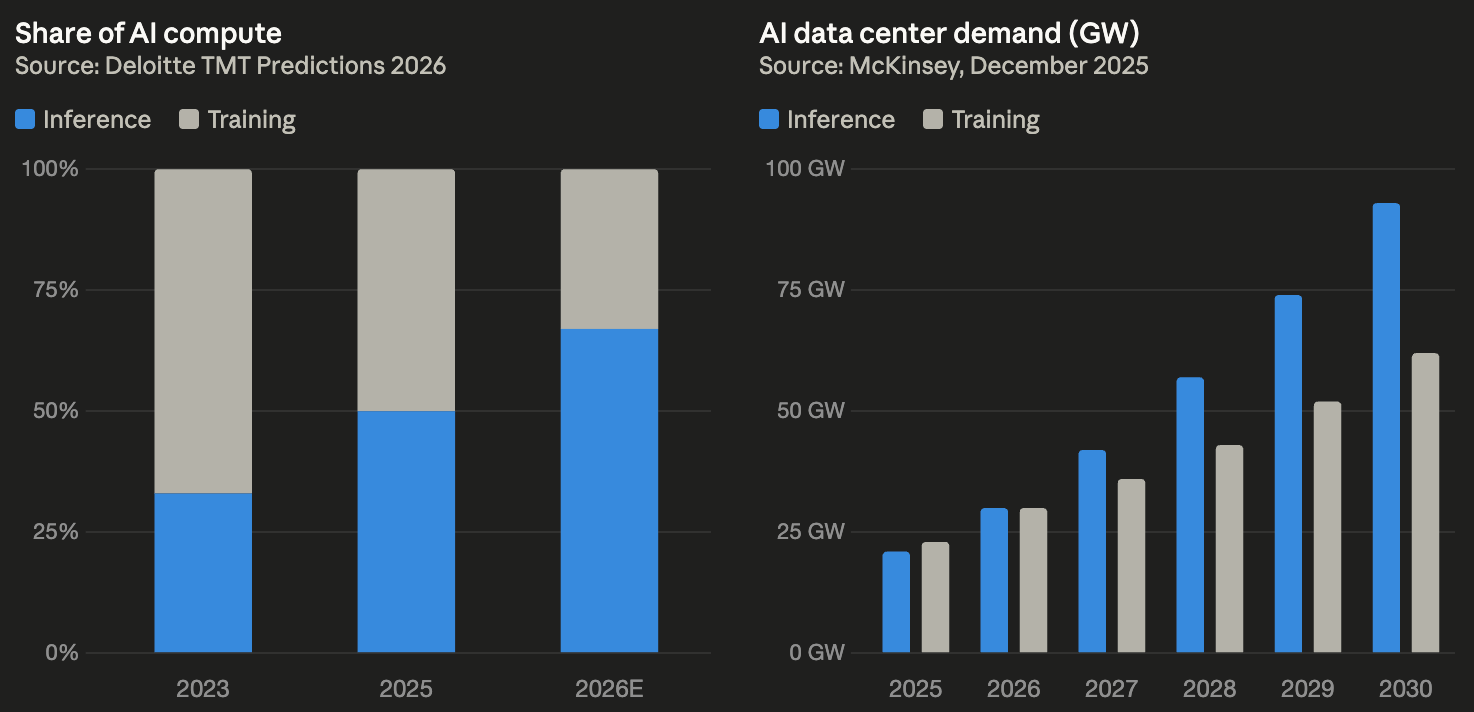
Inference accounted for roughly a third of AI compute in 2023, climbed to half in 2025, and is projected by Deloitte to hit two-thirds by the end of 2026, with the Futurum Group expecting it to overtake training in both volume and dollars this year.
Operators are drawing the same conclusion. At GTC 2026, Jensen Huang declared that “the inflection point of inference has arrived,” projecting that computing demand will surpass $1 trillion through 2027.
But the infrastructure to support this shift is moving more slowly. The Big Five hyperscalers have collectively committed $660 to $690 billion for 2026, roughly 75% of it tied to AI, and the bulk of that is still flowing toward training-class campuses in remote regions. This is where power is abundant, but has considerable distance to inference demand.
Training infrastructure is itself a moving target. Power densities, cooling, and interconnect topologies evolve each chip generation, and a campus built for 2023’s training workload may struggle to serve 2027’s, let alone retrofit cleanly into inference. Some campuses will adapt. Some will be repriced for lower-margin workloads. A meaningful number will be stranded between two workloads they can’t quite fully serve.
Training is a Cost Center…
In the first half of the decade, frontier model training was the scarce resource everyone was racing for, and the optimization logic was simple: maximum compute, location irrelevant. GPT-4 was trained on an estimated 25,000 A100 GPUs running for roughly three months on a Microsoft supercomputer in Iowa.
The location was chosen for power and cost, with proximity to users never factored in. You spin up a cluster, run a job for weeks, and shut it down.
Inference is a Revenue Center…
Inference is a revenue center where every query is a transaction and every API call a billable event. For a decade, the industry rented GPUs by the hour, paying by the clock regardless of utilization. Inference turns this inside out, converting GPUs into revenue-generating factories priced by output / outcome. The GPU serving an agent closing a sales deal is worth far more per hour than the same GPU batch-processing documents for training overnight.
Over a model's lifespan, inference can comprise 90% of total cost, and the gap only widens as models stay in production longer.
Operators that serve inference most efficiently can turn the cost advantage into structural pricing power.
The Mismatches
Inference, however, has fundamentally different physical requirements than training, and most of the capital deployed so far has been optimized for the latter.
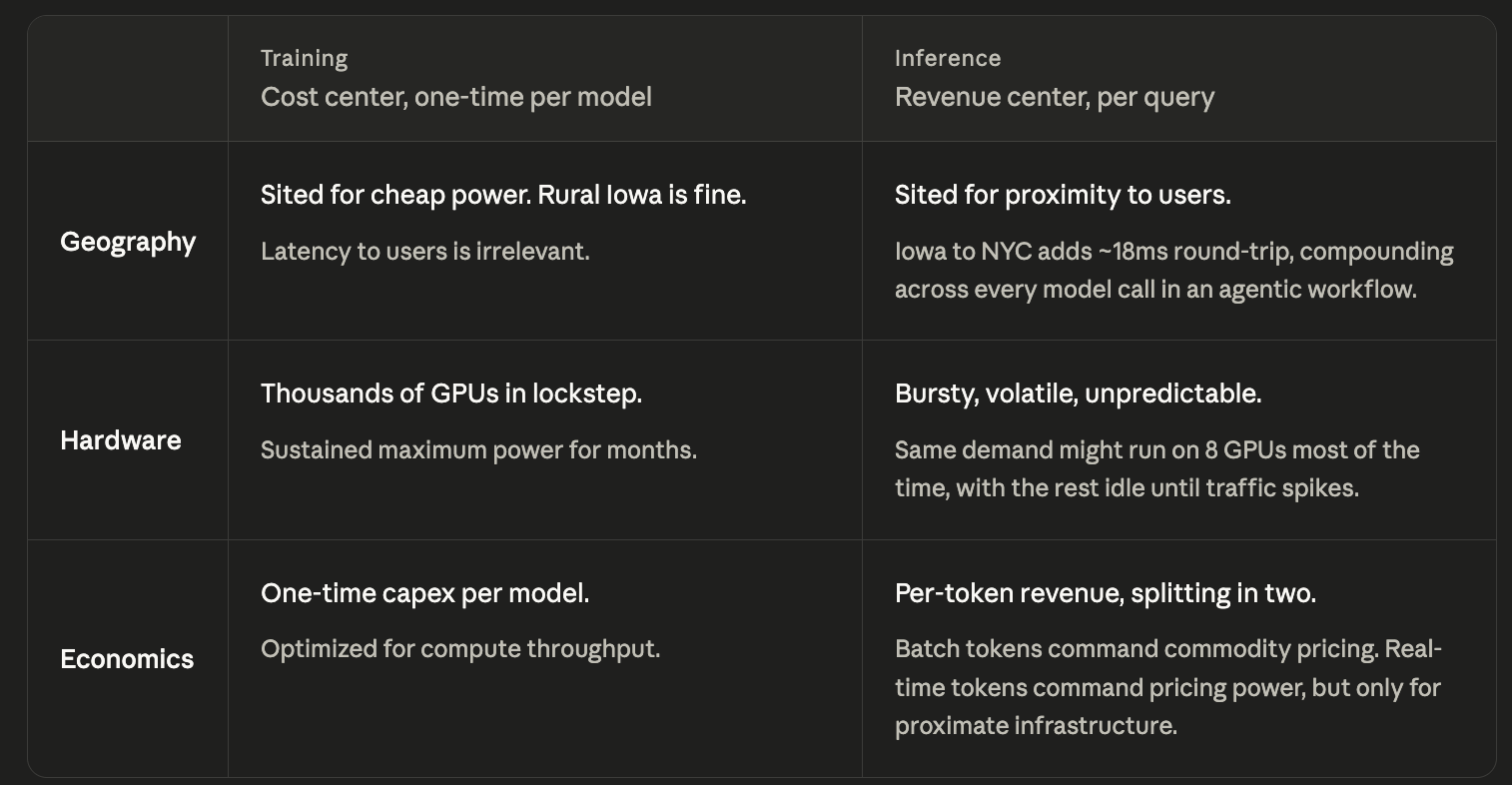
A facility sited for cheap power instead of proximity carries the latency penalty. The cooling, redundancy, and power delivery assumptions behind a training facility do not translate cleanly to bursty inference.
The Stranded Asset
AI is short-cycle compute embedded in long-cycle real estate, and the chips inside a campus refresh faster than the campus can be re-sited or re-powered. The instinct to repurpose existing training clusters as they age out runs into both constraints.
The most exposed today are the neoclouds. Companies like CoreWeave and Lambda built their businesses on renting H100 GPU clusters for training, but they are simultaneously squeezed by two forces: frontier labs increasingly building their own infrastructure rather than renting, and inference needing different chips in different locations than what the neoclouds provisioned.
The economics of GPU rental were already fragile: McKinsey puts gross margins at 55 to 65 percent before depreciation, with a limited buffer if utilization dips or rental prices slip. H100 rental rates have declined 60 to 75 percent from their peak, CoreWeave’s debt-to-equity ratio exceeds 7x, and neocloud deal flow is stalling over credit and underwriting risk.
Three outcomes are emerging for affected assets:
a) repricing for batch inference at reduced margins,
b) conversion to next-generation training as model scale keeps growing, or
c) genuine stranding, where rural and single-purpose facilities face a geography fall-short that is hard to fix.
The AI buildout asked how to train the best models, but the AI economy asks a different question: how do we serve inference to billions of users cheaply, everywhere, at the speed that makes new products actually work?

My hypothesis is that part of the solution sits within infrastructure that already exists but isn’t yet “priced” as AI infrastructure.
Building new data centers in metro areas is slow. Power interconnects take years, land is expensive, and permitting is a fight. Telecom networks already have buildings in every population center with power, fiber, and cooling in place. Most of that footprint is now underutilized, since voice and consumer traffic moved to the cloud. Slotting GPUs into telecom real estate is one of the fastest, cheapest ways to put inference compute near users without greenfield construction.
The carriers are already moving. T-Mobile’s 85,000 cell sites and 100 core network locations form what its chief network officer calls the densest grid in the US, and the carrier is piloting inference systems at cell sites and mobile switching offices. Verizon has launched AI Connect for hyperscaler workloads. At GTC 2026, NVIDIA and a coalition of carriers unveiled the “AI grid” to deploy GPU inference across distributed telecom infrastructure.
A parallel buildout is happening at the micro data center layer. Companies like Vapor IO are deploying compact, modular data centers directly at cell towers and fiber hubs, slotting compute into the same telecom real estate from a different angle. Vapor IO plans to deploy across 50 metros, targeting 500 locations by the end of 2026, and currently operates its Kinetic Grid in six live metro markets with 26 additional cities permitted.
The hyperscalers are already adapting their new builds. About 70 percent of new core campuses now combine general compute and inference workloads, and market leaders are siting new facilities in metro areas with the flexibility to serve both.
The more exposed assets are inflexible facilities that were purpose-built for training in locations chosen for cheap power rather than proximity, by operators without the balance sheet or optionality to retrofit.
Rahul Narula is a Strange Research Fellow and an MBA candidate at Harvard Business School. He previously worked in product operations at Cruise, where he helped scale robotaxi fleet operations, and has a background in data science and operations across data centers.
EVENT
Interested in AI and design? Join us for a private demo of MagicPath with founder Pietro Schirano next Thursday in San Francisco.
Strange Magic Hour: Design

 |
|