

The Liquid Revolution: Inside the Racks That Can Heat 160 Homes
Next-generation compute racks will drive up the complexity (and opportunity) in data center operations

In this week’s GTC keynote, NVIDIA announced the deployment of its impressive Vera Rubin NVL72, which ships in H2 2026. It packs 72 Rubin GPUs, 36 Vera CPUs, and more in a single liquid-cooled rack, and its power consumption can exceed 200 kW.
To put that in context: an average U.S. home draws about 1.25 kW. One Vera Rubin rack consumes 600kW, and nearly all of it becomes heat - the equivalent of roughly 160 homes. Remove that heat, or the chips throttle, and the $3 to $4 million machine becomes a very heavy paperweight.

The next rack architecture after Rubin, Feynman, is named for 2028, and NVIDIA’s rack power roadmap points toward megawatt-class densities. Each generation pushes rack power significantly higher, and the cooling problem compounds with it. Once racks reach a certain power draw, air, which carries roughly 3,500 times less heat per unit volume than water, becomes infeasible.
The industry is racing to solve the heat problem, from subsea data centers to launching servers into orbit. But the most likely answer is: liquid cooling.
Interestingly, the hardware is a fraction of liquid cooling’s real cost. The bulk is in operations, like the mean time-to-repair when something breaks in a system that has failure modes most facilities teams have never seen.

Liquid cooling is not new; data centers have used chilled-water loops for decades. What is new is the intensity of energy required. A traditional air-cooled rack runs at 10 to 15 kW, and aggressive airflow engineering can push that up to about 40 kW. But the Vera Rubin can exceed 200 kW, and at those levels, air stops being a practical medium for heat removal. The bottleneck becomes the ability to move heat out of the system.

Modern deployments solve this by moving the cooling problem directly onto the hardware. In direct-to-chip systems, coolant flows through cold plates mounted on CPUs and GPUs, absorbs heat, and carries it out before transferring it to the facility loop or an external rejection system. Immersion systems go further, submerging servers in dielectric fluid that absorbs heat directly, and in some cases boils and condenses in a continuous cycle. Both approaches eliminate fans and support far higher densities, but they introduce different operational tradeoffs. Direct-to-chip systems are generally easier to service, while immersion systems can handle higher thermal loads at the cost of added complexity.
This is not a continuation of earlier liquid systems. Older deployments were built around lower densities and looser assumptions. A chilled-water mainframe room is not comparable to a 200 kW rack, much less to a warm-water system on a path toward megawatt-scale densities. Today’s systems are hotter and more operationally demanding, and even facilities that have used liquid cooling before often lack the controls and service model required at these densities.
The shift to warm-water systems makes that break more explicit. Vera Rubin’s 45°C inlet specification departs from legacy chilled-water loops and even from current direct-to-chip systems. At the chip level, there is still thermal margin. At the system level, the design basis changes. In many climates, heat can be rejected directly to ambient air using dry coolers, reducing dependence on chillers and evaporative systems. This lowers capital cost, reduces energy consumption, and cuts water use, but it also raises the system’s baseline temperature, narrowing the time available to diagnose and respond when something goes wrong.
Adoption: Early and Uneven
Most data centers still rely on air, but the shift to liquid is underway. Industry projections suggest liquid cooling will be installed in 40% of sites by the end of 2026. Hyperscalers and AI-native operators like Microsoft, Google, Amazon, and Meta are standardizing on it, while most enterprise and colocation providers remain one to two hardware generations behind.
New AI halls are being designed around liquid from day one. Existing facilities are retrofitting what they can, carving out high-density pods while keeping the rest of the campus air-cooled. Retrofit is possible, but extremely costly. Some sites will be upgraded in phases. Some will be reserved for lower-density inference. Some will simply be repriced as they fall out of the frontier tier.
This creates a fragmented operating environment: mixed cooling architectures, uneven power distribution, and systems running at very different density and thermal profiles within the same facility. Liquid solves the heat problem, but it introduces a different kind of complexity. Pumps, manifolds, valves, sensors, fluid chemistry, and safety procedures become part of the operating stack. As the number of components increases, the number of failure modes increases alongside it.
This is the hidden cost of the transition: hydraulic debt. Operational complexity accumulates quietly until it surfaces as downtime.
The Operational Opportunity
A pressure drop or flow anomaly can point to several different root causes at once. It might be a micro-leak at a fitting, a degrading pump, drifting telemetry, or slow corrosion inside the loop. In an air-cooled room, a temperature hot spot can suggest where to look. In a liquid-cooled rack, the signal is even more ambiguous.
Not every repair is complicated, i.e., the wrench time may only be ten minutes. But the localization time can be forty, and that gap is where the cost sits. In warm-water systems, the problem is amplified. Higher baseline temperatures compress the operational margin for diagnosing and responding to faults.
The usual first response to this complexity is monitoring: more sensors, better dashboards, earlier alerts. Monitoring is necessary, but a dashboard only surfaces symptoms. It can show that the temperature is rising on rack 14 or that the flow has dropped below a threshold. What it cannot do, in most implementations, is determine whether the underlying cause is a flow restriction, a failing pump, an incorrect valve state, or bad telemetry, nor can it recommend a safe intervention with high confidence.
At scale, this distinction becomes decisive, and it shifts the bottleneck from visibility to attribution and response.
The more durable opportunity sits one layer deeper: systems that take conflicting telemetry, reason about how the hydraulic loop is actually behaving, and produce a specific diagnosis (i.e. the failing component, the likely failure mode, and a confidence level) along with a recommended procedure and an audit trail. The output is a decision-support package that an operator can act on immediately, or that an automated system can execute within pre-approved safety boundaries.
NVIDIA is already designing toward this. Its GTC framing was explicit: AI infrastructure has crossed the point where human operators can manage it directly, signal volume exceeds human capacity, manual triage becomes a bottleneck, and system knowledge remains fragmented across individuals. The shift is from human-in-the-loop to human-on-the-loop. Agents handle detection, correlation, diagnosis, and remediation within guardrails, while operators move into system design and governance.
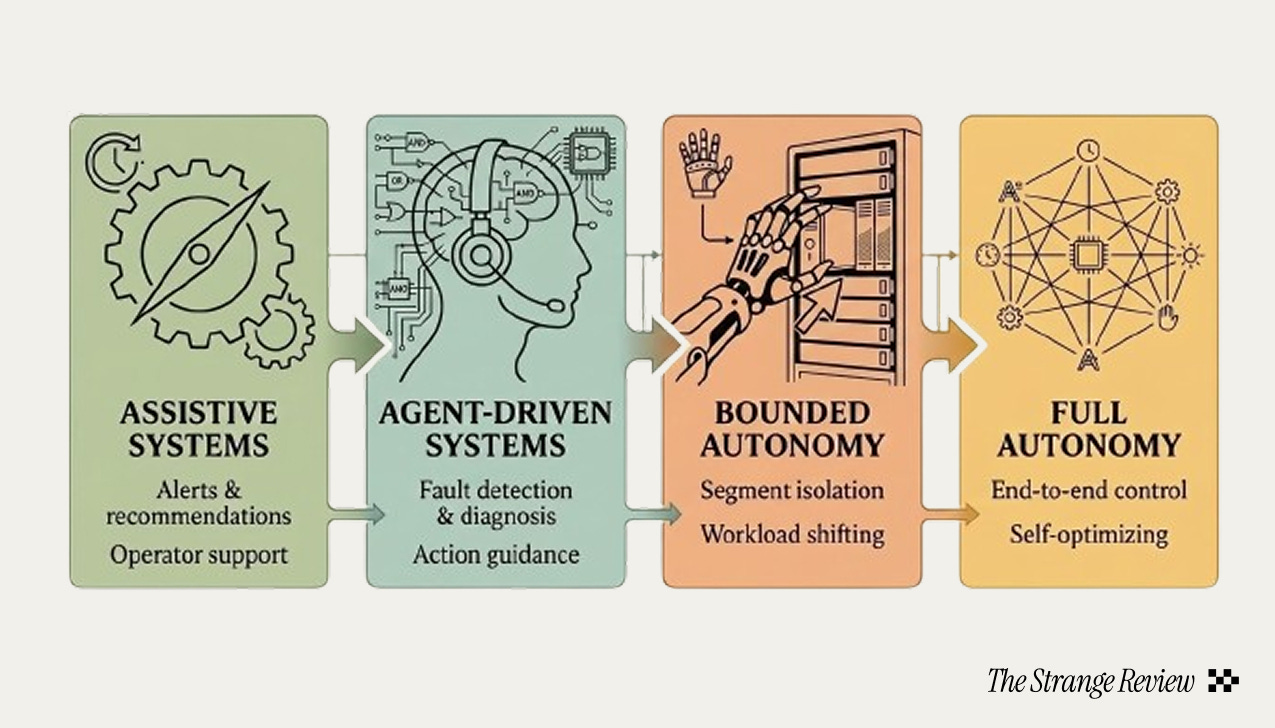
I believe the transition to autonomous operations will be staged. Today’s systems are assistive. The next phase is agent-driven: systems that localize faults, explain their reasoning, and recommend actions. Beyond that is bounded autonomy: systems that isolate a segment, notify the scheduler, and shift workloads. Full end-to-end autonomy remains further out, but the trajectory is clear.
In some environments, including edge deployments, sovereign AI sites, and early orbital systems, there may be no technician on site at all. In those settings, the shift from human-in-the-loop to human-on-the-loop is not an optimization but a requirement.
Where We Might Be Headed
The facility becomes the product. When a rack draws 200 kW and the roadmap points toward 1 MW within a few years, the data center is no longer generic real estate. Power delivery, cooling architecture, and structural engineering become differentiating capabilities.
The energy model inverts. At 45°C inlet water, the cooling plant simplifies: dry coolers instead of continuous chiller operation, closed loops instead of evaporative towers, waste heat at temperatures useful for district heating. Cooling energy as a share of total facility power drops, but operational sophistication has to increase. Pump reliability, flow management, filtration, and leak response all become more critical when the system is running warmer.
The cadence is relentless. NVIDIA shipped GB200 NVL72 in 2024. GB300 NVL72 in 2025. Vera Rubin NVL72 ships H2 2026. Feynman is named for 2028. Each generation notably increases the power density, and the cooling infrastructure now has to keep pace with an annual hardware refresh cycle.
The frontier rack already assumes liquid cooling. The harder problem, one I believe the market has not yet priced, is in operating it.
Rahul Narula is a Strange Research Fellow and an MBA candidate at Harvard Business School. He previously worked in product operations at Cruise, where he helped scale robotaxi fleet operations, and has a background in data science and operations across data centers.
 |
|