

Are we measuring the wrong thing in AI for Science?
Every leaderboard in AI-for-science measures the part of science AI is already good at. Is that true scientific progress?

In February 2025, researchers at Imperial College London handed Google’s AI Co-Scientist an unpublished problem they had spent roughly a decade working on: how certain bacteria acquire DNA that makes them harder to treat. Two days later, the system returned the same hypothesis the Imperial team had spent years validating in the lab. One of the co-authors put it plainly to the BBC: this was ten years of research, condensed into two days.
The result is striking, but the framing around it has been misleading. The AI compressed the hypothesis-generation step. But it did not compress the experiments.
“The system gives you an answer and that needs to be experimentally validated,” the Imperial researchers noted. Ten years of bench work did not collapse into 48 hours. Yes, one cognitive task did. The rest, the part of science that actually involves physical interaction with the world, remained exactly as slow as it was before.
This distinction matters because it maps onto a larger problem in how the field measures itself. AI systems are now powerful enough to saturate benchmarks designed to track scientific capability. They are not demonstrably good at the work those benchmarks were trying to proxy.
We are hosting an AI x Science Jeffersonian dinner in San Francisco! If you’re interested in attending, please request an invite here.

What today’s benchmarks actually test
The current generation of AI-for-science benchmarks share a structural feature: they are built around questions with known answers.
PaperBench, released in April 2025, asks AI agents to replicate 20 ICML 2024 Spotlight and Oral papers from scratch: read the contributions, write the code, run the experiments. The best agent scored 21%; ML PhD students given 48 hours scored 41%. FutureHouse’s Falcon hits roughly 90% on LitQA2, a graduate-level biology literature retrieval benchmark, against 67% for human domain experts.
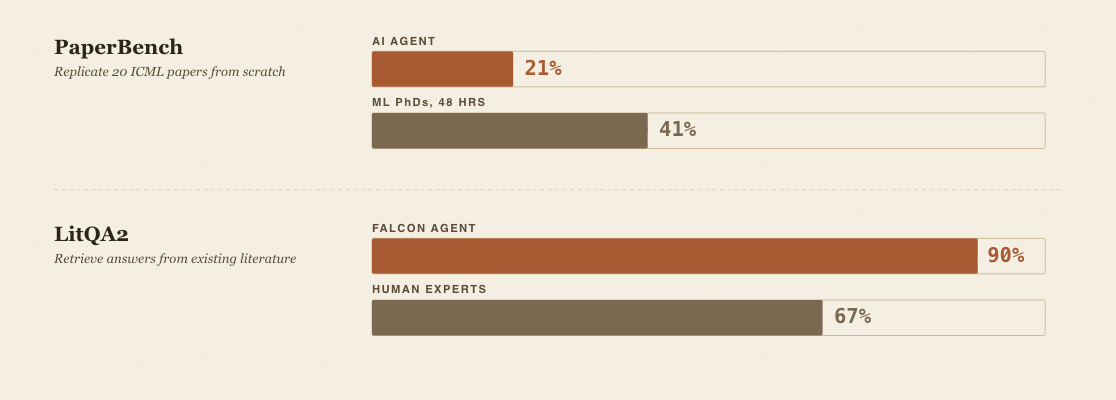
These are real measurements of real capabilities. They are also, almost without exception, measurements of convergent reasoning.
The questions were written by humans who already knew the answers. The “ground truth” exists because someone established it first. PaperBench, the most demanding of the set, measures the reproduction of work that has already been done. FrontierScience’s authors were candid about what their benchmark misses: it “does not capture many core elements of scientific work,” including hypothesis generation and experimental interaction.
Thomas Wolf, co-founder and chief science officer of Hugging Face, framed the deeper problem in a 2025 essay. Current benchmarks test whether AI systems can answer questions we already know the answers to, but
“real scientific breakthroughs will come not from answering known questions, but from asking challenging new questions.”
His argument has a technical edge: LLM training optimizes for the most likely next token under a distribution learned from existing human knowledge. The scientist who discovers something genuinely new is, by definition, producing a low-probability output under that distribution. The training objective and the target behavior are in tension at a structural level, not an incidental one.
Wolf’s proposed counter-benchmark is interesting precisely because it cannot yet be built: evaluate a model on a recent discovery it could not have been trained on, and see whether the model independently generates the right questions to reach it. This requires a corpus of problems solved after the model’s training cutoff where the solution was genuinely surprising. Building such a benchmark requires knowing in advance what genuine novelty looks like, which is the circular problem that defines the evaluation crisis.
The Imperial AMR case is the closest thing to Wolf’s test that has actually been run in the wild. The result was impressive on the hypothesis-generation axis. On the other axes that constitute scientific work, the AI was not tested.
Too many submissions?!
Anyone who has talked to a research editor or a scientific conference organizer in the last year has heard some version of this. Carlo Rovelli, the theoretical physicist and chief editor of Foundations of Physics, told TIME in 2025 that submissions to his journal had more than doubled in the past year.
A January 2026 Nature paper from researchers at Tsinghua and collaborators analyzed 41.3 million papers across six natural science disciplines from 1980 to 2025, using a fine-tuned language model to identify AI-augmented research.
Scientists who use AI publish 3.02 times more papers, receive 4.84 times more citations, and become research project leaders 1.37 years earlier than those who do not. AI adoption also shrinks the collective volume of scientific topics studied by 4.63% and decreases scientists’ engagement with one another by 22%. The authors call the result “lonely crowds”: concentrated activity on popular topics where individual papers attract more attention but where cross-citation and intellectual exchange between adjacent research programs declines.
This is the benchmark problem playing out in the actual literature. Scientists are using AI tools where AI tools are most effective, which is on tasks involving data processing and pattern recognition over existing corpora.
Most of it, he said, is people who think they are doing science by having conversations with LLMs. If AI is making it easier to produce plausible-sounding work, the rate of genuine discovery may stay flat or decline even as publication counts climb. The narrowing the Tsinghua paper measures and the degradation Rovelli is describing point in the same direction: yes, there is more output, but less of it that matters.
The Oxford Internet Institute documented a parallel problem at the benchmark level: only 16% of 445 LLM benchmarks they reviewed use rigorous scientific methods, and roughly half claim to measure abstract capabilities without defining those capabilities. Benchmarks create path dependencies. A system that saturates the available benchmarks is not the same as a system that is scientifically useful, and the closer the available benchmarks come to defining the goal, the more the development incentive pulls toward measurable proxies and away from the harder, unmeasurable capabilities.
Sara Hooker’s 2020 essay on the “hardware lottery” captured a version of this dynamic at the infrastructure level: research directions win when they happen to fit the tools that exist, not necessarily when they are universally superior to alternatives. Deep neural networks won partly because GPUs built for video games turned out to be good at matrix multiplies. The benchmark question is the same dynamic moved up one level. Fields with rich data and cheap iteration are getting the lift from current AI tools. Fields with sparse data or expensive experiments, often the ones where the highest-stakes problems for human welfare live, are not.
What better measurement would look like
I believe there are at least three proxies for real scientific impact worth tracking.
The first is topic diameter, the metric from the Tsinghua paper. Not how many papers a system generates or how many citations it accumulates, but whether the set of topics being actively researched is expanding or contracting as AI adoption rises. This is the most direct available measure of whether AI is opening new frontiers or accelerating work in established ones.
The second is the hypothesis-to-validation ratio: not just the rate at which AI systems generate hypotheses, but the fraction that survive experimental testing, and specifically the fraction that are genuinely novel rather than confirmations of prior work. This requires longitudinal data across research programs and is expensive to collect. It is also the closest available proxy for what actually matters.
The third is cross-disciplinary citation flow: whether AI-assisted research is increasing or decreasing the rate at which papers cite work from outside their primary domain. If the Nature finding on engagement decline is robust, it implies a specific failure mode worth tracking directly. AI tools may be efficient at retrieving the most relevant literature in a narrow domain and poor at surfacing the distant, unexpected connection that historically produces paradigm shifts.
OpenAI’s own researchers acknowledged the underlying problem when they wrote that “the most important benchmark for the scientific capabilities of AI is the novel discoveries it helps generate.”
This is correct and, for now, aspirational rather than operational. Novelty cannot be established at the time of generation. It can only be recognized later, as a community of peers evaluates whether something genuinely unexpected happened. The Imperial AMR result was impressive precisely because the Co-Scientist’s hypothesis could be checked against a decade of independently produced experimental work, a form of ground truth that almost no benchmark replicates.
Building AI for science evaluation frameworks that is built on post-hoc validation against independent experimental results would be slower and more expensive than what exists now. They would also tell us something real.
The empirical question worth holding the field to is not whether AI can match human performance on difficult scientific tasks. That question is being answered, affirmatively and quickly.
The question is whether the tasks AI matches humans on are the ones that produce scientific progress. The benchmark architecture currently in use cannot distinguish between the two.
Mason Rodriguez Rand is a Strange Research Fellow who holds degrees in molecular and mechanical engineering (UChicago, UC Berkeley) and has led engineering and go-to-market efforts at climate and energy startups out of Argonne National Lab and UC Berkeley, spanning nuclear, carbon removal, and advanced materials.
 | A guest post by
|
A thoughtful reminder that metrics can easily become proxies for progress instead of progress itself. In AI, biotech, and startups alike, measuring the wrong thing often creates the illusion of momentum while missing real-world impact.